Solving Raven's Progressive Matrices (RPM)
artificial-intelligence
 by
omniji
by
omniji
Background
The goal of Knowledge-Based AI is to create intelllegence comparable to human. To evaluate the intellegence of an AI agent, we let it take the same intelligent tests that humans take -- the Raven’s Progressive Matrices (RPM) test of intelligence. The figure below shows a typical example of a RPM inspired problem that the agent faces:

Verbal & Visual
There have been two broad categories of aproaches to RPM -- verbal abd visual. Verbal approaches represent the RPM problem in terms of verbal representations, in which the contents of the figures are described in a formal vocabulary. The Visual approaches try to solve the RPM only with the images themselves. In this report, both approaches are experimented.
Verbal Approach:
The experiment first started with easy RPM problems with only sizes of 2X2. Semantic networks are used to represent the relation between figures.
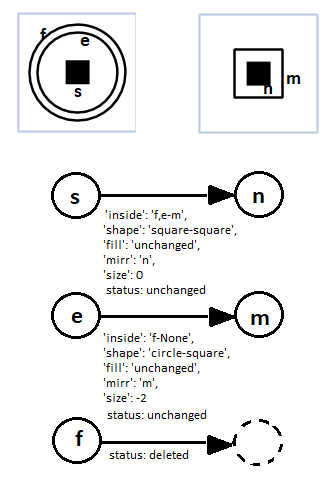
The semantic comparison was then done in 3 directions -- horizontal, vertical and diagonal. The total score of similarity will be the sum of the score in these 3 directions.

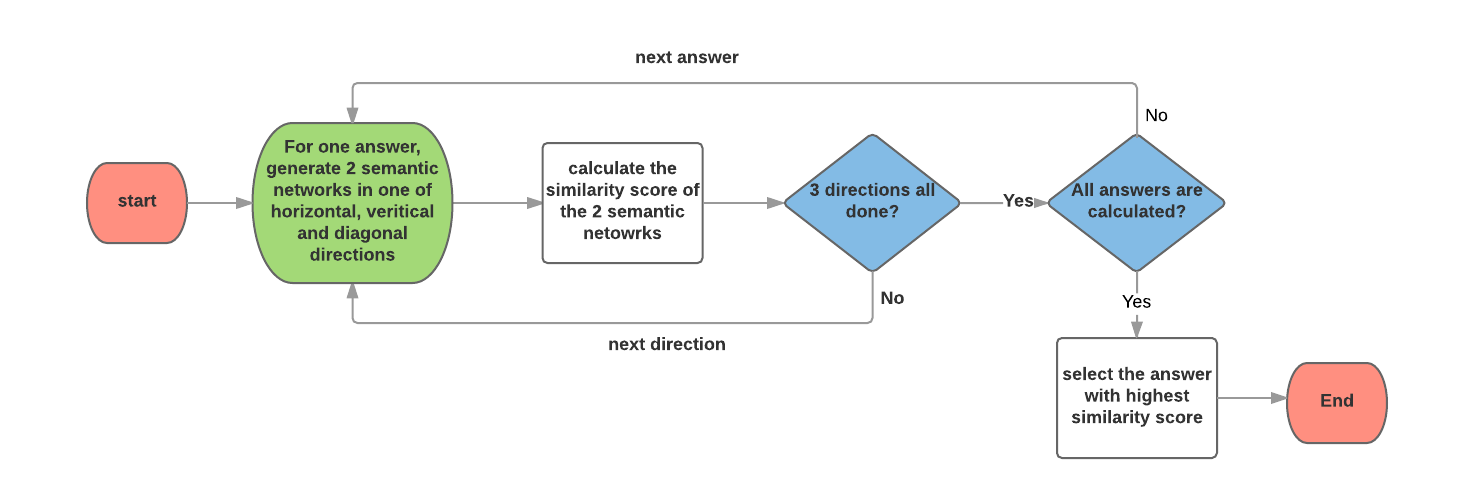
This process is iterated over the 6 answers of the problem, and the answer with the highest similarity score will be selected. Figure below shows a flowchart of the process.
However when the size of RPM increases, for example to 3x3, the information that need to be stored increased drastically(4x)
to compare semantic networks in all 3 directions. So instead of using semantic networks to represent all the shapes and their transitions between 2 figures, only the differences were represented.
For example figure A & B in figure below:
Previously , the semantic network of A & B will be

Now it only contains the differences between A& B:

The agent then picks one direction to solve the problem:
If A diff B == B diff C,
Then compare (D diff H) with (H diff I). // I is one of the answers
Else,
Compare (E diff F) with (H diff I)
Limitations :
1) Relies heavily on pre-defined shape features, and won’t perform will when unknown information are presented, lacking the knowledge to process the new information properly.
2) Not able to process visual information. As numbers of shapes increase and relations become more complex, it will become difficult to define all information and will be vulnerable to errors.
Visual Approach:
Chanlllenges when solving 3X3 RPMs with the visual approach include:
Challenge 1: Extract information of shapes in figures
In the verbal approaches, relations between figures can be represented for each one of the shapes. However it’s difficult in visual approaches, requiring more graphic analyzation to transfer visual info to verbal info.A large amount of basic knowledge of each shape will be needed.
Challenge 2: Misalignment between shapes in the figures will introduce noise to the Visual calculations.Shapes located differently are easy for human to recognize, but difficult for the agent. For example, in Basic Problem E-04, it’s easy for humans to tell that figure C is figure A minus the block in figure B. However since the location of the block in figure B is different from that in figure A, the agent won’t realize they’re the same shape.

Design key points:
1) Simplifying the grey scale
Slight difference in the gray scale can introduce noise to the calculation, but won’t be noticed by human agents. Thus the P3 agent ‘sharpens’ the grey scale of the figures into an array of 0 and 1 instead of pixels.
2) Affine Model & implementation
Affine model was used to find transforms between figures.
When trying to transform figure A to B, It first apply 14 basic transforms to figureA, including :
-- Rotate 0, 45, 90, 135, 180, 225, 270 degrees;
-- Rotate the 7 degrees above, then flip.
Then the transformed figure is compared to figure B pixel by pixel, and a score of similarity is generated:
-- Score of Similarity = (number of pixels that are the same)/(numbers of pixels that are different)
The basic transform that gives the highest similarity with figure B will be selected as the best transform, then an array of the same size with the figures(Diff Array) will be build to represent the differences in pixel level.
3) Deciding Directions for comparison
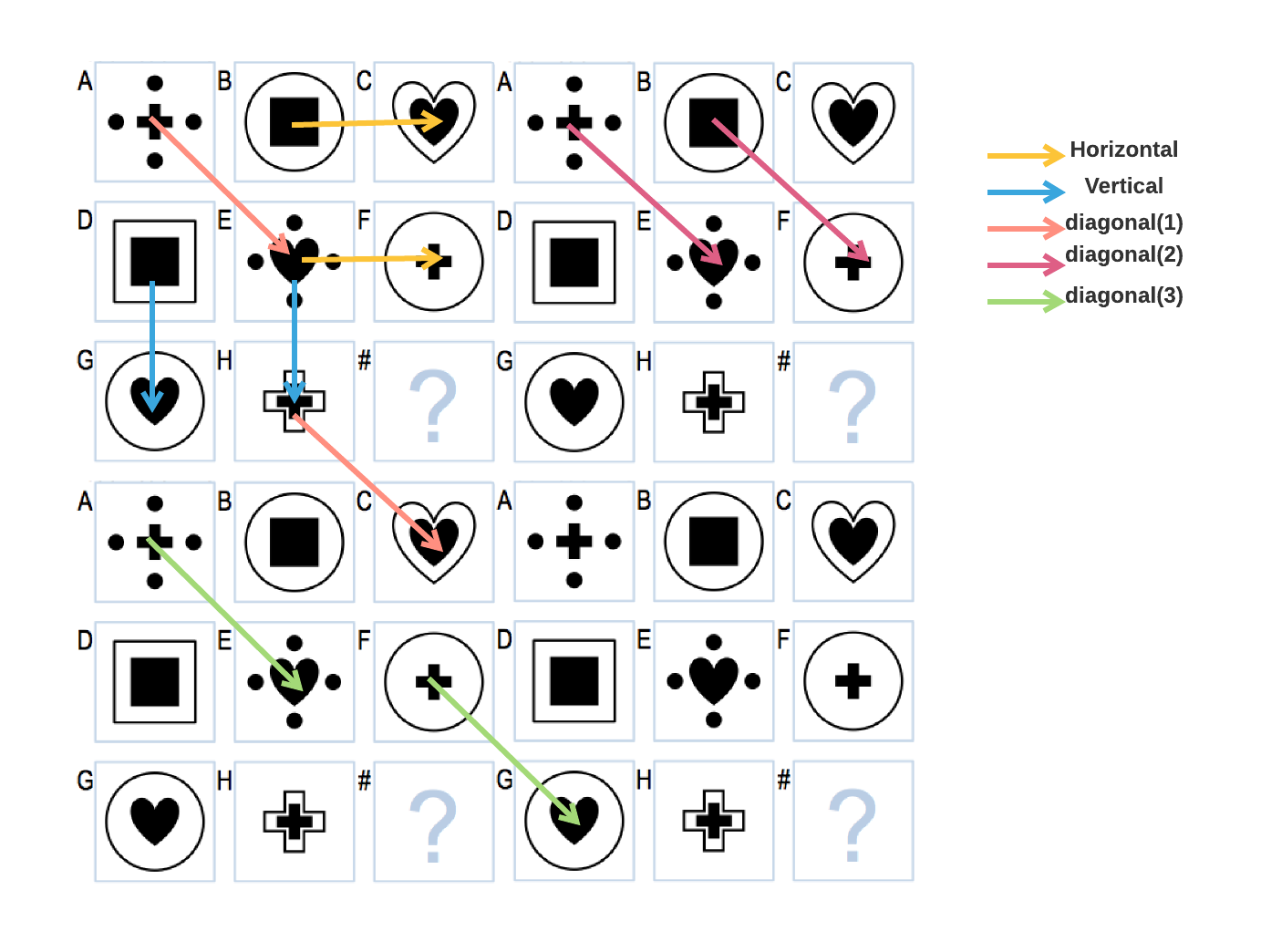
Only the array that represents the difference between 2 figures will be compared. Most of the problems can be solved by comparing and applying the differences in 1 direction. For example in Basic Problem D-07, we can see that in diagonal direction A(diff)E = F(diff)G, which indicates G(diff)B = E(diff)I, as shown in the figure below. The “I” in the equation stands for the answer. Only one direction is sufficient here.

To decide the best direction, the agent needs to calculate the score of similarity of the known figures in all directions. 5 directions are iterated, as shown in the figure below. For each direction there are 2 arrows in the figure below, indicating 2 groups in the direction. The differences between the 2 groups will be compared and generate a similarity score. The group with the highest score will be selected.
4) OR, AND, NOT, XOR: Logic operation between figures
The Affine model does not cover most of the problems in set E, which mostly consist of problems related to the logic operations between figures. Thus Or/And/Not/Xor was introduced. Only the horizontal direction is compared for the logic operations at this point and seemed to have a good enough performance.
In summary, below is a flowchart of the Visual agent:
4. Agent Capabilities
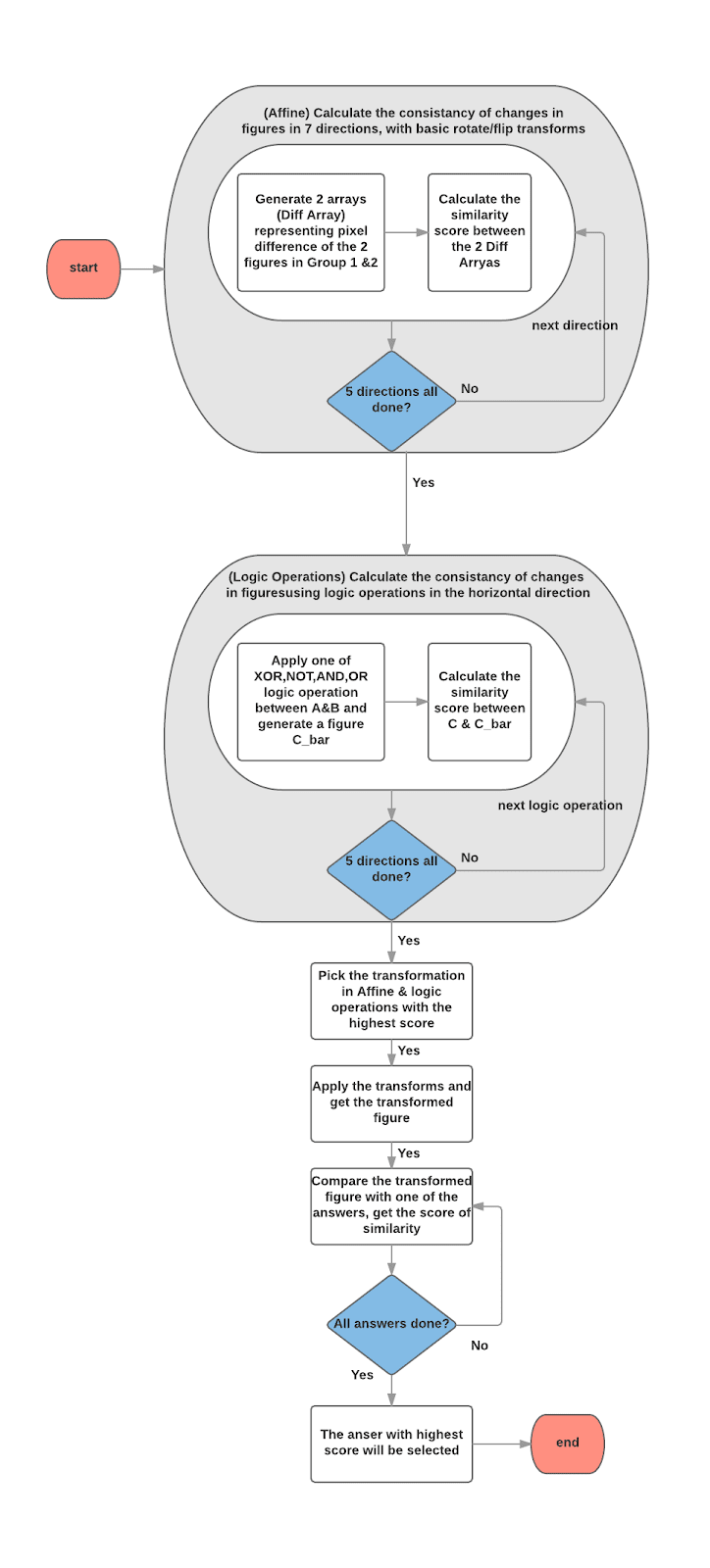
The main componenåt of the agent include:
1) GetFigureSharp
“Sharpen” the figure to an array of “0” and “1”. When the grayscale of a pixel is >128, it will be translated to “1”, and “0” vise versa.
2) GetFigureDiffSharp
Get a “Diff Array” between 2 figures. The array is of the same size with each one of the figures’ pixel array. When comparing the pixel at row “y” and column “x”, the resulted DiffArray[x][y] = Sharpened_figure_A[x][y] - Sharpened_figure_B[x][y].
3) GetSimilarity
Calculate the score of similarity =(number of sharpened pixesl that are the same) / (number of sharpened pixesl that are different)
4) GetTrans
Generate 2 “Diff array” of the 2 groups in one of the7 directions mentioned in part 3, by trying 14 basic rotation & flip transforms. The transform results closest to target will be selected. Then the transformed figure and target figure will generate a “Diff Array” using function “GetFigureDiffSharp”.
The similarity score of the 2 “Diff Arrays”, as well as the type of the basic transform will be returned.
5) ApplyFigueDiff
Apply the figure differences marked by “Diff Array”. This will result in a new sharpened figure with the differences added from the previous comparisons.
6) Affine
Pick the best direction by similarity scores of “Diff Array” in each directions.
7) AandB, AorB, AnotB, BnotA, AxorB
These functions apply logic operation between figure A & B, then compare it with C. The operation with the highest score will be selected, if Logic transform will be used.
8) Solve
Pick the one with highest score among all the logic transforms and Affine transform. Apply the differences and generate a test figure. Pick the answer closest to the test figure.
Agent Limitations
Mistakes due to figure misalignment:
The visual agent does wrong in problems below.


The locations of the figures changed from figure to figure. In D-12, Humans can tell that from A to E, the squares become stars. However the agent cannot tell this “replacement” relation due to location change. All the calculations or rotate, flip, and logic operations cannot work well when the shapes are not aligned very well.
A possible solution is calculating the percentage of dark pixels in the figures, and the change of this percentage in each directions. When the figures are not aligned, the scores of the Affine transforms and Logic transforms will be low. Thresholds can to set to screen the cases that need the dark pixels approach.
Independent rules in different portion of figure:
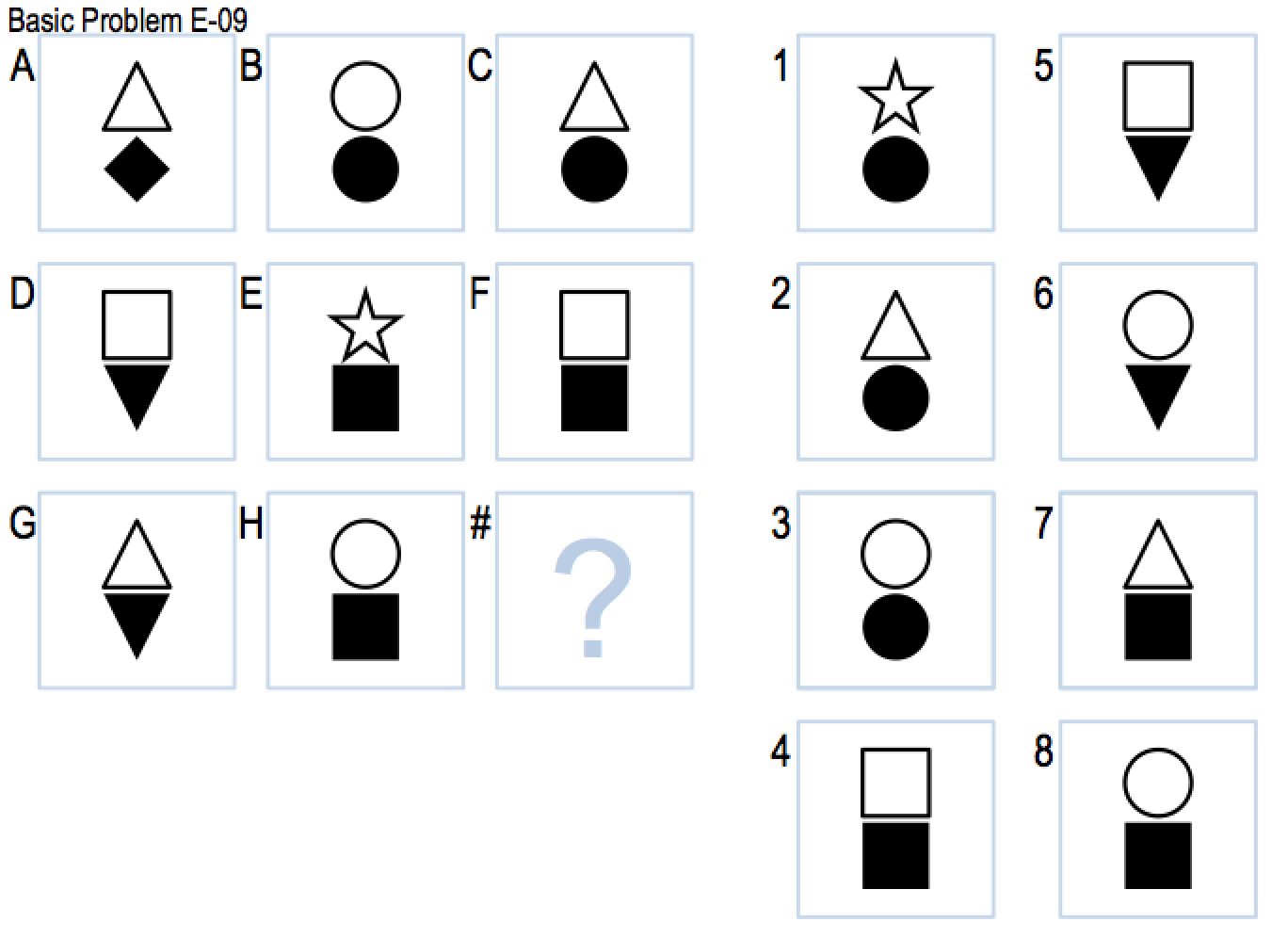
In problem E-09, the agent gives identical score on answer 7 ,8 because the upper and lower half of the figures follow independent changing rules. A possible solution is to separate the figures into sub-figures and independently use the Agent3 methods for each one of the sub-parts.
Previous mistakes:
Previously the P2 (verbal approach) made mistake on C-12. Agent P3 gives correct answer on this, since the figures are well-aligned.

However it does very bad on other problems when the same shape moved its location and were not aligned. Lacking the ability to extract the shape information from the figures.
5.2 Generality:
P3 has some improvements on the generality when compared to P2. P2’s verbal approach relies highly on the pre-defined shapes and features, and won’t process problems with undefined information very well. On the other hand P3 has some ability to apply pixel level differences to figures, but is still somewhat limited to some pre-defined conditions. For example it cannot solve when shapes moves left or right. Some extra process on the figure like cropping needs to be defined.
5.3 Efficiency
The efficiency of the P3 significantly decreased as compared to P2 (verbal approach). With visual approach, P3 has to calculate each one of the pixels in the figures, which is a massive calculation. It has to go through the arrays several times to calculate the feasibility in each directions and each transforms.
Agent relation to KABI
1) Case based Reasoning
The P3 agent uses Case Based Reasoning solving 3x3 problems. It studies the patterns of each directions first, then does the case adaption by rules (heuristic adaptation) to generate a test figure for the final answer.
2) Generator and test
The P3 agent uses Generators and tests. After getting the result of the optimal direction and transformations, it generates a reasonable answer, then compare it to each one of the options. In P3, the generator takes more work since it reasons over all possible transforms to get an optimal answer.
3) Production Rules
This is used when deciding which kind of transformation will be used. The agent chooses from the Affine transforms and logic transforms using the rules on their scores. In future improvements when the percentage of dark pixels & sub-portion transforms are introduced, more rules will be needed to decide between the methods.
Agent relation to human cognition
The P3 agent is closer to human in a way that it’s able to abstract some useful information visually from the figures. It can also apply the visual differences to the figures to existed ones, or calculate grayscale percentages. This process is similar to humans visually processing the figures.
However the information P3 agent can abstract from the figures is limited. When human look at the figures they will know the changes of shapes, locations, sizes. They can quickly correlate 2 shapes at different places with different sizes together. On the other hand, all the all the information the P3 agent abstracted is an array of pixel differences. It won’t be able to tell the change of the shapes’ features by looking at the Diff array. All it knows is an array of “0”s and “1”s and tries to compare it to another array. It’s not able to correlate the shapes too different together unless certain pre-processing is done on the figures, like cropping to shape boundaries or cutting the figures into several pieces.
When P3 does has solutions to similar problems stored ( stored all transforms in all directions), it picks the optimal transform and filters the less optimal ones. This is also similar to human cognition. When people think about possible solutions, they can have several ideals, then “score” the choices in their minds and pick the best one.
References:
[1] KBAI EBOOK: KNOWLEDGE-BASED ARTIFICIAL INTELLIGENCE. (Bhavin Thaker, David Joyner, Ashok Goel, Oct 2016
[2] Maithilee Kunda, Keith McGreggor, and Ashok Goel. A computational model for solving problems from the Raven’s Progressive Matrices intelligence test using iconic visual representations. Cognitive Systems Research (2012)